Keep your soft sensors reliable in production.
STAMM is an open-source MLOps framework for monitoring and maintaining machine-learning soft sensors in live industrial processes — detecting drift, tracking versions, and keeping your digital twin aligned with the real world.
An operational layer for your soft sensors.
Moving ML models into production is not trivial. STAMM treats your soft sensor as a living component of the process — tracking data, monitoring drift, and surfacing when maintenance is needed, without prescribing how the model should be rebuilt.
Real-time deployment
Integrate existing soft sensors into live systems alongside physical instruments — no rewrites required.
Drift detection
Catch gradual or abrupt changes in operating regimes before they silently degrade prediction quality.
Model registry
Track multiple versions of the same model across deployments with full traceability and metadata.
Dashboard
Provides real-time visualisation, drift monitoring and human-in-the-loop labelling.
The soft-sensor lifecycle, managed end-to-end.
From the moment a soft sensor is deployed, STAMM watches it like an experienced operator — tracking inputs, stability, and outputs so you can trust what the model is telling you.

Deploy
Plug an existing soft sensor into live process data.

Observe
Stream measurements alongside hidden variable estimates.

Detect
Identify regime shifts and concept drift in real time.

Signal
Raise maintenance flags only when it actually matters.

Evolve
Track versions over time for continuity and traceability.
Built for the people who keep models honest in production.
STAMM sits between the lab and the factory floor. Whether you build the models, run the process, or supervise the digital twin, STAMM gives you a shared, observable layer to work from.

Process Modelers
Experts in Process Engineering who design and validate soft sensors using mechanistic or hybrid models. They ensure predictions remain physically and biologically meaningful, and interpret model behavior as process conditions evolve.
See their journey →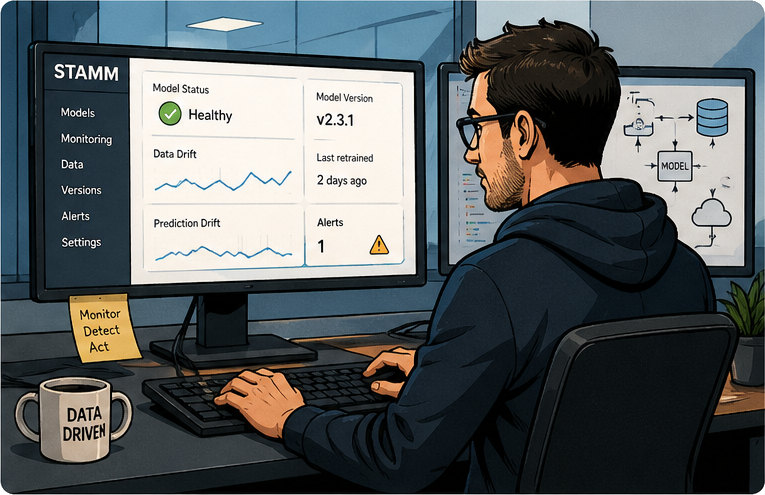
ML engineers
Specialists in MLOps who deploy, monitor, and maintain soft sensors in production. They manage pipelines, versioning, and retraining, ensuring models run reliably over time.
See their journey →
Operators
Frontline users who run the process in real time. They rely on soft sensor outputs for day-to-day decisions and need clear, immediate indicators of trust and stability.
See their journey →
Project Leaders & Process/Production Managers
Responsible for overall process outcomes, timelines, and risk. They use high-level insights from systems like STAMM to ensure reliable operation, support decision-making, and maintain alignment between models and the real process.
See their journey →A modular architecture, built to extend.
Each STAMM module is specialized for a single concern and communicates through clean APIs, so you can update, replace, or integrate pieces without rewiring the whole system.
Model Registry
The home for every soft sensor STAMM manages.
Each model lives here alongside its full configuration, artifacts, validation results, and rich metadata — from architecture and training parameters down to input variables and expected ranges.
- Versioned lineageEvery retrain becomes a tracked version with metadata — never a silent overwrite.
- Python & R supportSoft sensors built in either ecosystem are first-class citizens.
- REST inferenceModels are served over HTTP — no model code installed on the platform.
Dashboard
The operational window into your process.
Physical measurements, soft-sensor outputs, drift signals, and historical context — all on one screen, so operators can trust what they’re acting on and modelers can see how the system behaves over time.
- Live data + predictionsMeasured signals and soft-sensor outputs side by side, in sync.
- Drift monitoringRegime-aware indicators that surface real changes, not noise.
- Simulation assessmentReplay batches and validate models against ground truth.
Time-series Database
STAMM’s reference & live data backbone.
A pluggable time-series store for raw measurements, model predictions, and variable metadata — InfluxDB today, with a PostgreSQL adapter being added so STAMM can plug into other databases under a unified schema.
- Reference & live dataHistorical batches alongside the current process state.
- Pluggable backendsInfluxDB now, PostgreSQL adapter in progress, more to follow.
- Unified taggingDevice, project, and batch tags make traceability automatic.
Workflow Orchestrator
The conductor between data, models, and predictions.
Watches the database for fresh measurements, calls the Model Registry to score them, and writes predictions back — reproducibly, event-driven, end-to-end.
- Event-driven DAGReacts to new data instead of polling on a fixed schedule.
- Remote model callsTalks to the Model Registry over REST — nothing installed locally.
- Timestamp-aligned outputsEvery prediction stays linked to the snapshot that produced it.
Drift Detectors
Tell when the model is guessing.
A standalone Python package (drift_detectors_pack) that compares current input distributions against the reference window each soft sensor was trained on — surfacing interpretable drift scores so the dashboard, and the team, can spot when conditions move away from familiar territory.
- 10 detectors, one interfaceUnivariate, multivariate, and model-based families behind a single API.
- Self-describing metadataEvery detector ships a metadata.yaml the dashboard renders automatically.
- Pluggable into pipelinesInstallable as a Python package — usable inside or outside STAMM.
Try STAMM on IndPenSim.
Our reference demo applies STAMM to an industrial-scale penicillin fermentation simulator — with a Node-RED bioreactor, curated dataset, and working model registry.
Dataset
Curated fed-batch fermentation data.
Open IndPenSim fed-batch fermentation data with annotated hidden variables — ready to plug into the demo registry.
Node-RED bioreactor
Streaming simulator, one Docker command away.
A realistic Node-RED bioreactor you can run locally with Docker — emits live process data to drive the full STAMM pipeline.
Papers behind STAMM.
The STAMM preprint explains each component in detail. The publications below describe models that ship in the demo model registry.
Built by engineers and researchers across Europe and Latin America.
Developed as part of the European project BioIndustry 4.0 — with equal contributions across design, development, and refinement.
Team






Collaborators
Contributing domain expertise, review, and institutional support.


Alumni
Past contributors who shaped STAMM and have since moved on.

In collaboration with
STAMM is developed under the BioIndustry 4.0 European project and the IBISBA Research Infrastructure.