Node-RED replay service
🔴 Node-RED replay service
A low-code data replay layer that streams IndPenSim batches into STAMM as if they were arriving from a live 100,000 L penicillin fermentation — so you can exercise the full stack without a physical reactor.
What it does
Node-RED is a flow-based, low-code development tool commonly used in IoT and industrial automation. It lets you wire up data sources, processing nodes, and outputs in a visual editor — ideal for rapidly building streaming pipelines without writing boilerplate.
In the STAMM demo, Node-RED is the data replay service: instead of connecting to a physical bioreactor, it replays historical IndPenSim trajectories and publishes them as time-series data. From the database, orchestrator, and dashboard's perspective, the virtual data stream is indistinguishable from a real reactor publishing online sensor data.
Pre-recorded fed-batch trajectories — batch2.csv, batch15.csv, batch60.csv, etc.
Each row becomes a standardized observation — variable, value, units, and contextual tags.
Unified schema: device_obs with tags device_id · project_name · batch_id · source.
The Node-RED dashboard
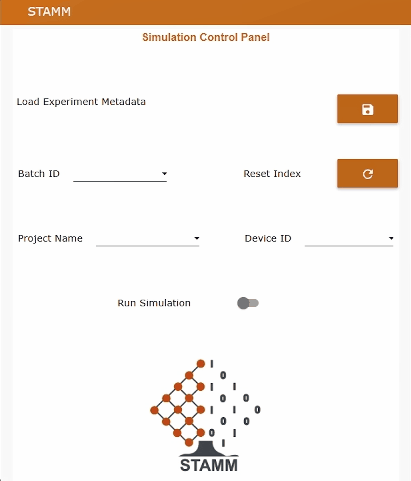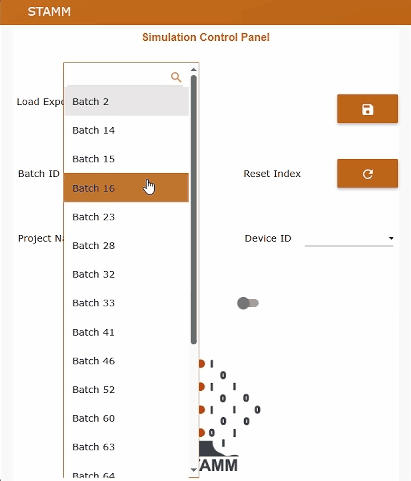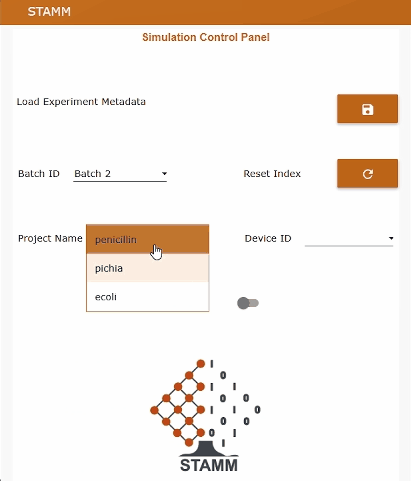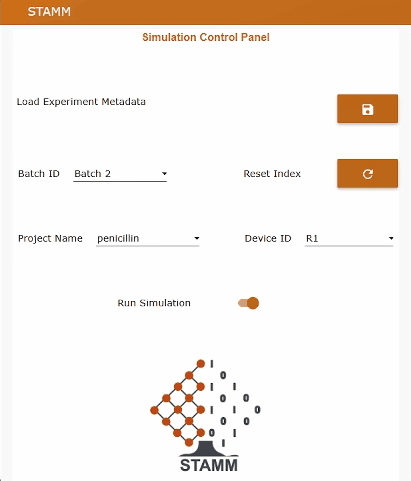
The Node-RED dashboard exposes an operator-friendly UI that lets you:
batch2.csv, batch15.csv, batch91.csv…penicillin, pichia, ecoliR1–R4stamm_metadata with labels and unitsEvery few seconds (by default, every 20 s), the data replay service sends the next row of the selected batch, preserving the original dynamic profiles and relative timing. This makes it possible to test the whole STAMM stack — time-series storage, soft sensors, and dashboards — without physical access to a 100 m³ bioreactor.
Deploy with Docker
The Node-RED data replay service is distributed as a Docker-based stack that can run on its own or alongside a full STAMM deployment.
📦 Requirements
Docker and Docker Compose installed, plus a running InfluxDB 2.7 instance with buckets stamm_raw and stamm_metadata.
⚙️ Configure the env
Copy .env.example to .env in the simulator repo and fill in the values below.
# Node-RED
NODERED_PORT=1880
# InfluxDB
INFLUX_BASE_URL=http://influxdb:8086
INFLUX_ORG=stamm
INFLUX_BUCKET_RAW=stamm_raw
INFLUX_BUCKET_META=stamm_metadata
INFLUX_TOKEN=YOUR_INFLUXDB_TOKEN_HERE
# Default tags for the data replay
DEFAULT_PROJECT_NAME=penicillin
DEFAULT_DEVICE_ID=R1
DEFAULT_BATCH_FILE=batch2.csv
STREAM_INTERVAL_SECONDS=20