STAMM modules
A modular architecture, built to extend
STAMM is built on a modular and extensible architecture designed to support scalable, reliable, real-time soft-sensor deployment in industrial environments. Each module is specialized for a single concern and communicates through clean APIs — so any piece can be updated, replaced, or integrated independently, without rewiring the whole system.
System architecture
The diagram below illustrates how STAMM's modules connect — from the time-series database all the way to the operator's dashboard, with drift detectors monitoring the soft sensors in parallel.
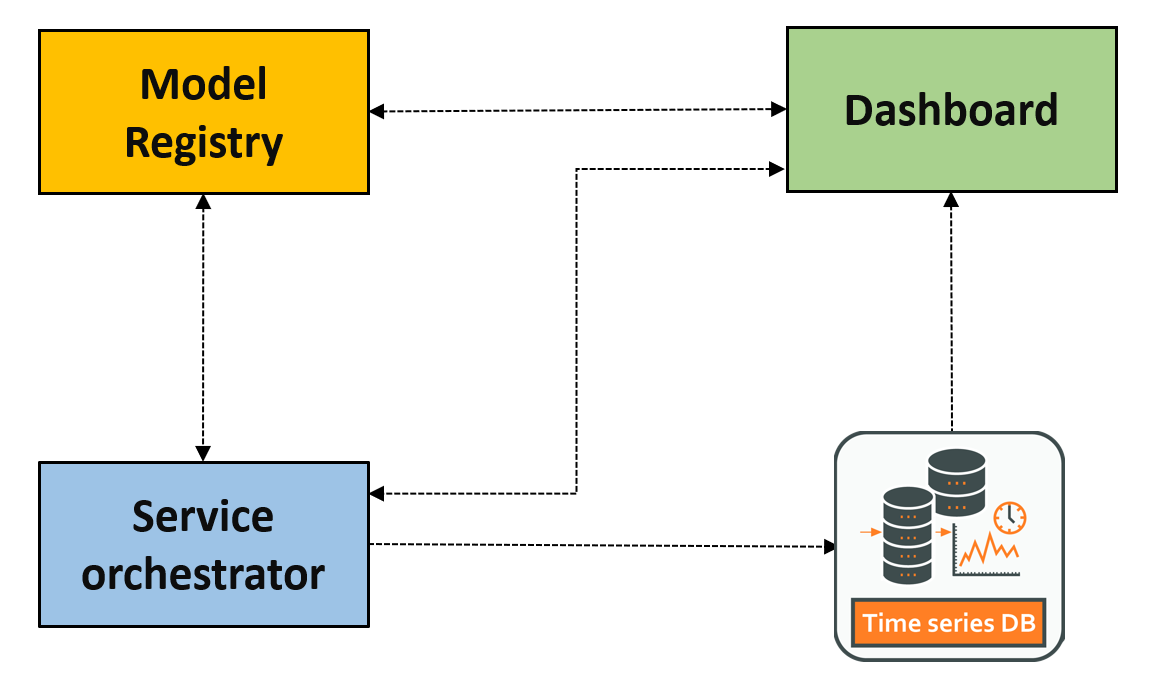
How the data flows
A single soft-sensor reading is the result of every module doing its job in order. Here's what happens between the physical process and the operator's screen.
🛢️Time-series DB holds reference & live data
Reference data (from historical batches) and live measurements from physical sensors and actuators land in STAMM's time-series database — InfluxDB today, with a PostgreSQL adapter being added so other backends can plug in under the same schema.
⚙️Workflow Orchestrator queries the DB
The Apache Airflow orchestrator continuously queries the time-series DB for fresh measurements and assembles snapshots of the current process state. Event-driven by design — soft sensors stay synchronized with whatever the process is doing right now.
🗂️Model Registry loads & serves the model
The Orchestrator calls the deployed soft sensor in the Model Registry over REST — no model code runs on the orchestration platform. The Registry loads the right model version and returns the prediction, fully traceable by model ID and version.
🛰️Drift Detectors evaluate the inputs
In parallel, the Drift Detectors compare the current input distribution against the reference window the model was trained on. They produce interpretable drift scores — univariate and multivariate — that tell whether the model is still working in familiar territory.
📊Dashboards surface everything to humans
The Plotly-based dashboards receive model predictions, reference and live data, and drift scores — and put them on one screen. Operators see trust signals, modelers see trends, and managers see operational risk in context.
The five modules in detail
Each module is owned by a different concern. Click through to the deep documentation for configuration, APIs, and examples.
Time-series Database
A pluggable time-series store for raw measurements, model predictions, and variable metadata. InfluxDB is the production backend today; a PostgreSQL adapter is in progress so STAMM can plug into other databases under the same schema.
- Reference & live dataHistorical batches alongside the current process state.
- Pluggable backendsInfluxDB now, PostgreSQL adapter in progress.
- Unified taggingDevice, project, and batch tags make traceability automatic.
Workflow Orchestrator
Watches the time-series DB for fresh measurements, calls the Model Registry to score them, and writes predictions back — reproducibly, event-driven, end-to-end.
- Event-driven DAGReacts to new data instead of polling on a fixed schedule.
- Remote model callsTalks to the Model Registry over REST — nothing installed locally.
- Timestamp-aligned outputsPredictions stay linked to the snapshot that produced them.
Model Registry
Stores, versions, and serves every soft sensor in STAMM — together with its configuration, artifacts, validation results, and rich metadata describing architecture, training, and input/output variables.
- Versioned lineageEvery retrain becomes a tracked version with full metadata.
- Python & R supportSoft sensors in either ecosystem are first-class citizens.
- REST inferenceModels served over HTTP — no model code on other modules.
Drift Detectors
A standalone Python package — drift_detectors_pack — that compares current input distributions against the reference window the soft sensor was trained on. Produces interpretable drift scores so the dashboard, and the team, can spot when conditions move away from what the model knows.
- Univariate & multivariateDetects shifts in single variables and in joint distributions.
- Interpretable scoresDrift signals come with metadata, not just numbers.
- Pluggable into pipelinesInstallable as a Python package — usable inside or outside STAMM.
Dashboard
An interactive Plotly-based web app that brings together physical measurements, soft-sensor outputs, drift scores, and historical context — built for operators, modelers, and project leaders alike.
- Live data + predictionsMeasured signals and soft-sensor outputs side by side.
- Drift monitoringDrift scores from the detectors surfaced with context.
- Simulation assessmentReplay batches and label outcomes for traceability.
How the modules communicate
STAMM keeps the boundaries between modules deliberately thin and explicit. There are three communication patterns:
The Orchestrator calls the Model Registry over HTTP. Inference happens where the model lives, not on the orchestration platform.
Raw data, predictions, and metadata live in the same time-series DB with consistent tagging, so any module can read what it needs without coupling.
Each model carries a YAML descriptor — architecture, inputs, outputs, training parameters — that the Registry, Orchestrator, Drift Detectors, and Dashboard all read from.
The result is a system where you can swap the database, replace the orchestrator, or rebuild the dashboard independently — provided each piece keeps its end of the contract.